What
Tried to build a tool to find “Atlas Obscura-like” places in Northern Germany using open data. The plan was to query OpenStreetMap (OSM) 1 for specific tags, filter for notable items (with the help of LLMs), and plot them. The big vision is to have a map of interesting, lesser-known places to explore during a road trip from one place to another, with an efficient route through these hidden gems.
Why
I like finding unusual spots. Atlas Obscura is great. I wondered if I could use OSM data to find similar places, especially in a region I’m interested in, like Northern Germany. The idea was to see if I could systematically surface hidden gems based on how they’re tagged. I already worked with mapping at my day job, and also for ICML 2024 on a map, so it should be a very quick PoC.
How
Initial Idea: OMF + Wikidata
Started with Overture Maps. The idea was to use their ‘Places’ data, filter by categories, and then enrich with Wikidata 2 to find unique stories. DuckDB 3 was good for querying the OMF Parquet files from S3. Problem was, the OMF categories I looked at were often too broad, and the specific “obscure” tags I was hoping for weren’t consistently there for my target types.
Additional Thoughts & Community
Found a Reddit thread about an AO search-along-route tool. Key takeaway: finding “interesting” is hard, and OSM data quality can be inconsistent for this. Another OSM Community discussion mentioned that AO places usually have a Wikidata item with an Atlas Obscura ID (P7772). This seemed like a good starting point.
Pivot to OSM: Learning from Known AO Places
Switched to OSM. New plan:
- Get known Atlas Obscura (AO) places in Germany from Wikidata (using property P7772 - “Atlas Obscura ID”).
- For each AO place, find nearby OSM nodes using the Overpass API 4.
- Analyze the tags of these nearby OSM nodes to understand how AO-like places are typically tagged in OSM. Saved these tag frequencies to a JSON file.
This gave me a list of common OSM tags and key-value pairs found near existing AO sites.
Direct OSM Querying
Based on the tag analysis and my list of preferred place types (abandoned things, viewpoints, unusual history, etc.), I built a list of OSM tag filters (e.g., ["historic"="ruins"], ["natural"="waterfall"], ["amenity"="observatory"]).
The core idea for the Overpass query was to find nodes in my Northern Germany bounding box that:
- Matched one of my “interesting” base tags (like
historic=ruins). - AND also had a
websiteORwikipediaORwikidatatag (as a proxy for notability).
The Overpass QL query structure looked something like this (simplified):
[out:json][timeout:300][bbox:51.66,6.94,54.69,13.97];
(
// For historic ruins with a website OR wikipedia
( node["historic"="ruins"]["website"];
node["historic"="ruins"]["wikipedia"]; );
// For waterfalls with a website OR wikipedia
( node["natural"="waterfall"]["website"];
node["natural"="waterfall"]["wikipedia"];);
// ... and so on for all base tags ...
);
out body;A Python script generated this query, fetched the data using the overpy library, filtered out unnamed nodes, and then I used folium 5 to plot the results on an interactive map. Each marker showed the OSM node’s name and all its tags on click.
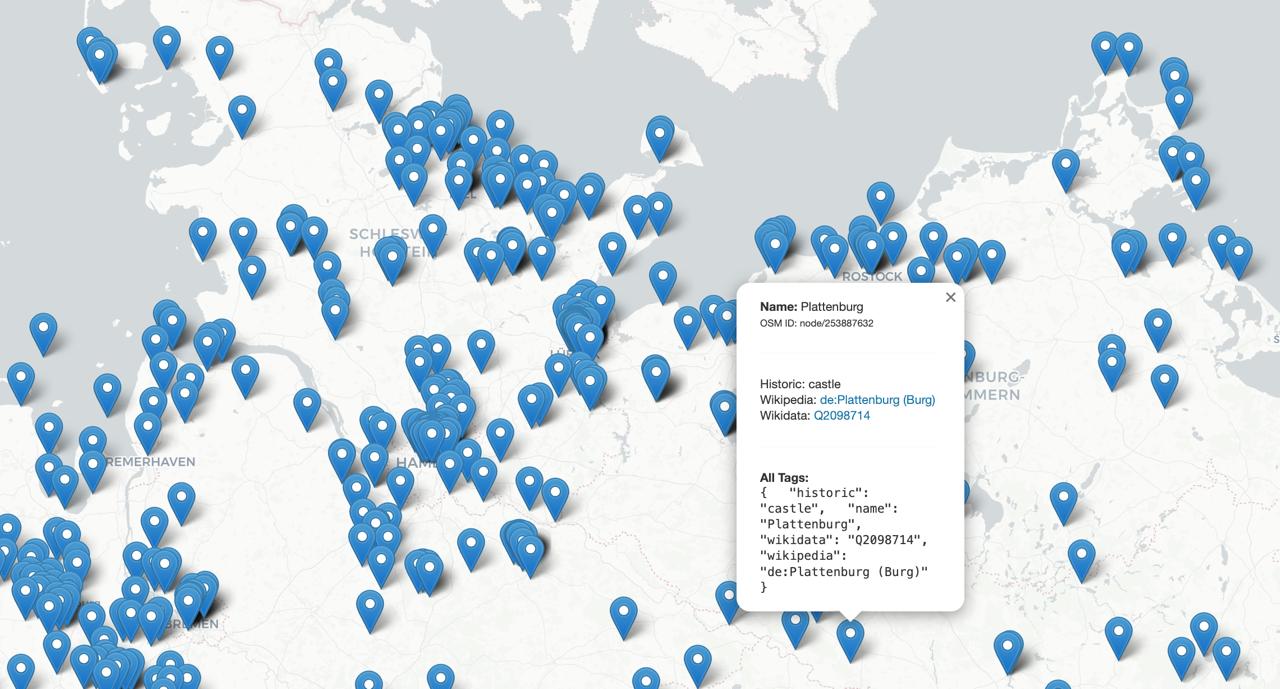 (Caption: Map of OSM nodes in Northern Germany from the direct query. Fewer points, more targeted.)
(Caption: Map of OSM nodes in Northern Germany from the direct query. Fewer points, more targeted.)
Current Approach & The “Good Enough” Point
The direct OSM query with the info-tag filter gave a much more manageable set of results compared to earlier, broader attempts. I got a CSV and an interactive map of these potentially interesting, named OSM nodes.
At this point, I realized that for my personal exploration, continuously refining the perfect automated script might be less efficient than using existing powerful tools. I can get pretty far with:
- Overpass Turbo (on mobile or desktop) for quick, targeted OSM queries when I have a specific idea or am in an area. The query is here: Overpass Turbo Query.
- Atlas Obscura itself for curated content.
- Mapcomplete with nature tags to find specific nature-related places.
- Google Maps for general navigation and finding standard POIs.
So, I decided the current Python script and the generated CSV/map are a good “version 1” for this project. It successfully pulls relevant, named OSM nodes with extra info links. The next step is less about more automation and more about using these results and tools for actual discovery.
Lessons / Observations:
- OSM’s tagging depth is great for niche searches, but requires understanding common tagging patterns.
- Filtering by
website/wikipediatag presence is a decent heuristic for notability in OSM. - Directly querying Overpass for specific node types is much faster than trying to resolve complex ways/relations if point-like features are the main target.
- Sometimes, building the perfect automated tool is less practical than leveraging existing, flexible tools for the core task (like Overpass Turbo for ad-hoc OSM queries).
Next Steps
- Manually explore the generated CSV and map of Northern Germany nodes.
- Focus on contributing interesting finds back to Atlas Obscura or improving their OSM tagging if appropriate.
Footnotes
-
OpenStreetMap (OSM): A collaborative project to create a free editable geographic database of the world. ↩
-
Wikidata: A free and open knowledge base that can be read and edited by both humans and machines. It acts as central storage for the structured data of its Wikimedia sister projects including Wikipedia. ↩
-
DuckDB: An in-process analytical data management system, designed to be fast, reliable, and easy to use. Good for querying Parquet files. ↩
-
Overpass API: A read-only API that serves up custom selected parts of the OSM map data. It acts as a database over the web: the client sends a query to the API and gets back the data set that corresponds to the query. ↩
-
Folium: A Python library that makes it easy to visualize data that’s been manipulated in Python on an interactive Leaflet map. ↩