What
An interactive map of all institutions that published at the International Conference on Machine Learning this year. Find it at https://arxiv-cat.eamag.me/
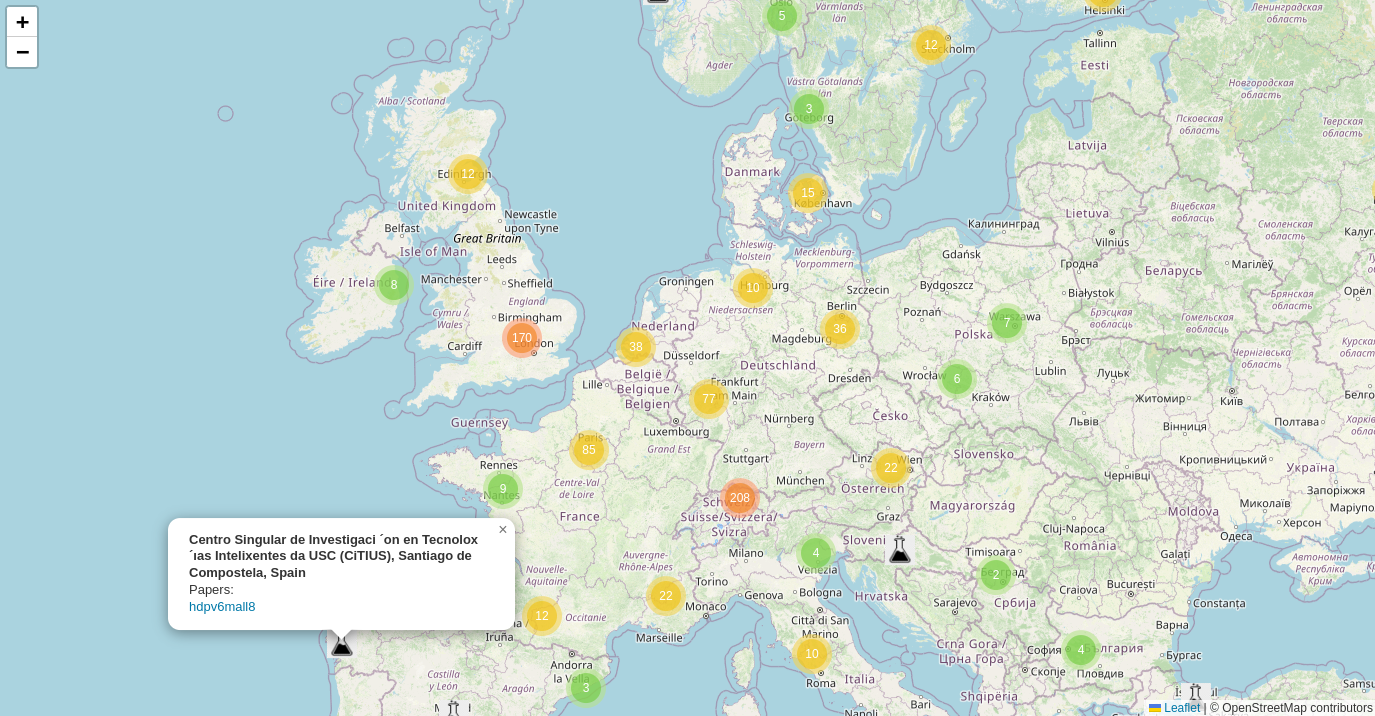
It can be useful for:
- Researchers to find collaborators nearby
- Industry to identify AI hotspots and hidden gems
- Institutions to understand their impact and competition
Why
I currently work remotely at Lyft building Lyft Maps, meeting some of my colleagues once a week in a coworking space here in Berlin. I noticed how we come up with new or better approaches to our problems more often when chatting in person. I also watched an amazing lecture by Richard Hamming called You and Your Research, where he talks about the benefit of keeping the door open.
Recently, I’ve become interested in AI research again, and I started wondering: who are the people around me that I can meet in person to chat about their advances? I knew there were good labs at TUB and Freie Universität, and I was also aware of some people at Amazon and Google here in Berlin doing research. But I thought, what if I’m missing some of them? I went googling but had trouble finding all the relevant information. So I decided to check who will publish at the nearest conference instead.
How
OpenReview
At first, I started manually searching for papers and browsing the ICML website, but that was slow and unproductive (there are 2634 papers this year!). I already had some familiarity with the OpenReview API based on my previous project Automated Paper Classification, so I decided to just get all papers and then see what affiliations authors specified in their profiles. I quickly found out that many people didn’t have OpenReview profiles, others had outdated info, or their affiliation was not relevant. So instead, I decided to parse the first page of each paper.
Extract affiliations
Even though every paper has the same format for a conference, because I couldn’t find a non-PDF source, I had to somehow parse the first page. I tried using regex first (with some help from LLMs, of course), but the extracted text from PDF couldn’t match any of my attempts. Instead, I started an LLM model (gemma-2) using ollama, extracted the first page from the PDF, and asked the AI to give me a mapping of authors to affiliations for each paper. After some prompt improvements, that worked quite well, with only 6 (out of 2634) papers unable to get a proper JSON output from the model. Previously, for HackerNews Prediction Evaluator, I used llama.cpp instead of ollama because I needed JSON every time, but here I can live with fixing 6 examples manually.
Lesson: many simple tasks are easy and free to solve using local LLMs, and it will only get better
Geocoding
In the true open-source spirit, I started getting coordinates of the institutions using Nominatim. Unfortunately, I saw many less-than-ideal results (for example, returning Facebook in Kenya as a first result), and trying many other services (ArcGIS, HERE, MapBox, Bing) I couldn’t get a good result either. But I could find the proper coordinates just by googling the affiliation, so after trying several things, I got the following error correction algorithm:
- Get coordinates from a Nominatim geocoder
- Use local LLM (ollama gemma-2) together with a Nominatim reverse geocoder to confirm the correct location (
here's the institution, here's the OpenStreetMap place returned by Nominatim, are they the same yes/no) - If not confirmed - google the institution, parse the first page, put all content into an LLM and extract the exact address (
here's the search result for the institution name, return an address) - Repeat steps 1-2 with an exact address
- If Nominatim still doesn’t work - use Google Maps paid API to get coordinates
This approach works. For universities, Nominatim usually finds a correct location at step 1, step 2 filters false positives like the example above, step 3 finds addresses of AI startups, and step 5 handles missing OSM data. With some manual overrides, we can finally put everything on a map.
Lessons:
- Simple open source place search doesn’t work well enough, there’s an opportunity to improve by adding ranking models
- We can enrich OSM data by using search + LLMs, but have to figure out the legal part
- There are many opportunities for a low importance error correction using LLMs
Mapping
It was fairly easy to put everything on a map in Python - just ask Claude to use folium and you get nice clustered points. However, I don’t really like Leaflet zooming, and I spent too much time trying different libraries to put this static data on my website. I already have a SvelteKit website, so I tried OpenLayers, MapLibre, and wrapper libraries for them in Svelte, but they all looked clunky or just didn’t work. I tried React and a simple HTML website, but in the end, the easiest way was to import Leaflet in the onMount function in my Svelte page and export the data from a static folder. Mapping on the web is still difficult, or did I miss some other obvious solution?
Lesson: don’t dive into web frameworks/libraries, start with basic established approaches (unless you found a template or a guide)
Next steps
There are still ways to improve it! Write to me on X or LinkedIn if you want to see some of them :)
- Better error correction, manual fixes
- Combine some of the labs/institutions into one
- Split some of the companies into smaller groups, find out where the work was done (for example, people contributed from Berlin but referenced just as Google Research)
- Add more conferences like NeurIPS 2024
- Make the same map for AI startups
- UI improvements
- Cleaning up the code and open-sourcing everything
- ???